Optimising Your GraphQL Request Waterfalls
As a technology, GraphQL is starting to gain traction. There are server implementations in a good selection of languages, and client support isn’t far behind. If you want to build your own GraphQL server, there’s plenty of information out there, but if you want to build an efficient one, there’s less guidance. I’ve been using GraphQL since it was a technical candidate, and have made plenty of mistakes along the way, but have been successful in making my GraphQL servers perform roughly as well as bespoke static endpoints.
I use Relay (a React library) on the client-side, and it requires a few conventions in your schema to function correctly. But whether you’re using Relay or not, you’re likely to find its conventions useful to follow. The most obvious one is to think in terms of Nodes, Edges and Connections:
Node — Typically represents an entity within your data model; could be a User, Blog Post, Product, Category, Transaction, Ticket, etc
Edge — Links two different Nodes together, which may or may not be of the same type. Conceptually, an Edge has a label indicating the nature of the relationship. For example, a financial Transaction between two Accounts would have an edge to each account, and their labels would indicate whether the account is sending or receiving the money
Connection — A grouping of edges that usually have the same label. For example, a Category could have edges connecting it to dozens of Products. A connection to Products from Category would give you the means to paginate over a list of products belonging to that category. If you’re interested in diving deeper into these concepts, check out “Exploring GraphQL Connections” by Caleb Meredith.
A fictitious example
To demonstrate my approach to optimizing GraphQL servers, I’ll use a simple example of a screen in an app/website that shouldn’t be too far removed from a real-world scenario. Then, I’ll transition step-by-step from a naive implementation to an efficient one. To clarify what we’re aiming for, an optimal GraphQL server is one that returns the data for any arbitrary query as efficiently as possible.
Some other terminology that you should bare in mind before we proceed:
Viewer — The person making the query. In the context of an app, this would be the logged-in user. A viewer may not be backed by a special type in your schema, but you’ll often have fields that have values varying depending on who you are.
Request — I’m using request to refer to an asynchronous call to your data backend. Depending on your stack, a request could mean a SQL query, HTTP request, RPC call, or any number of other things. As a convention, I always represent them as asynchronous function calls that return Promises/Futures. I also assume that the credentials of the viewer (e.g their auth token or ID) are implicitly made available to all requests, so don’t need to be provided in the function signature.
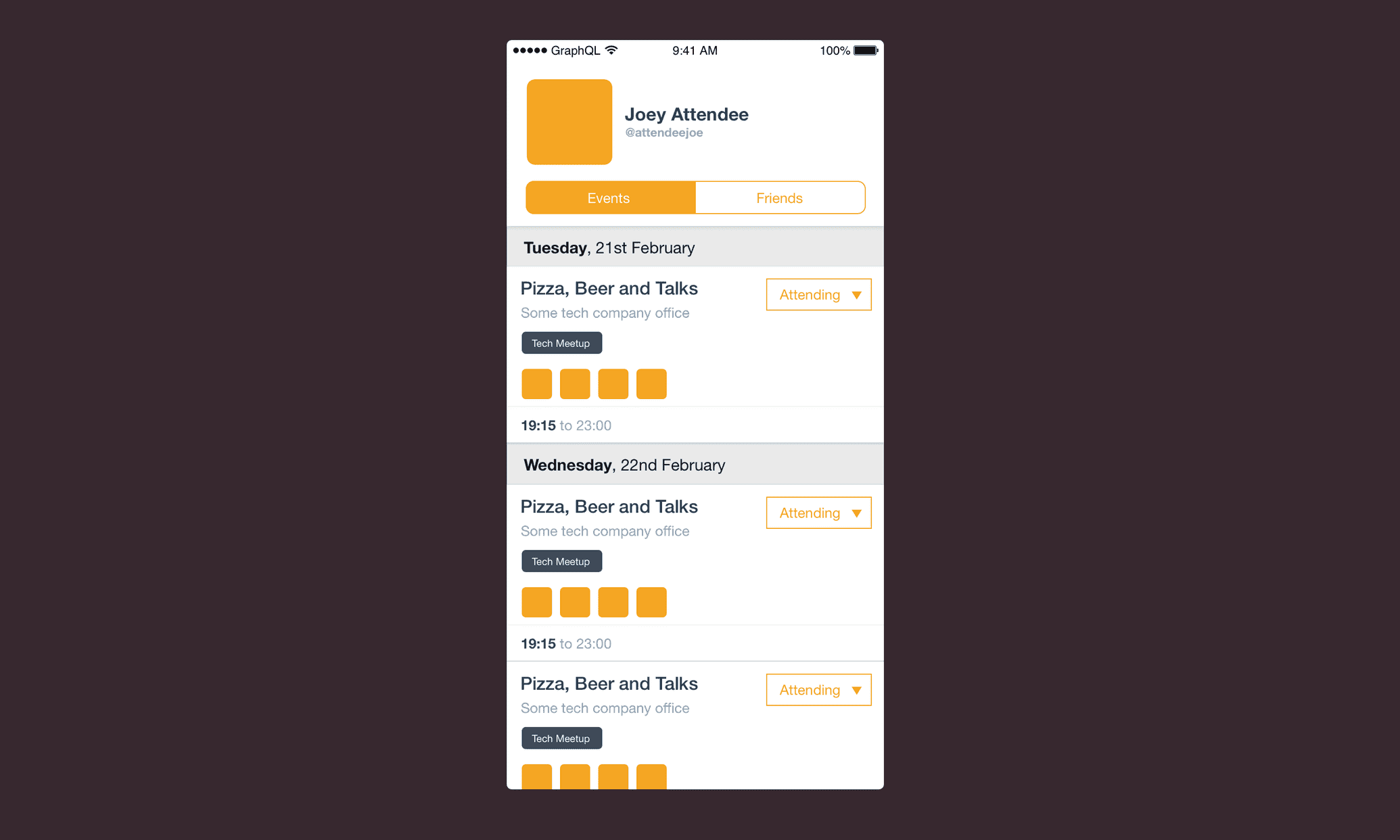
This mockup is for an events app — we’re looking at a screen which shows the list of upcoming events for some user (not necessarily the viewer). Each event card includes details about its venue, tags and a list of the viewer’s friends that are attending. We also show whether the viewing user has RSVP’ed for each event. This example has been constructed to represent a believable, real-world use case (it’s similar to real screens I’ve built), and also one that we’d expect to have poor performance if implemented naively.
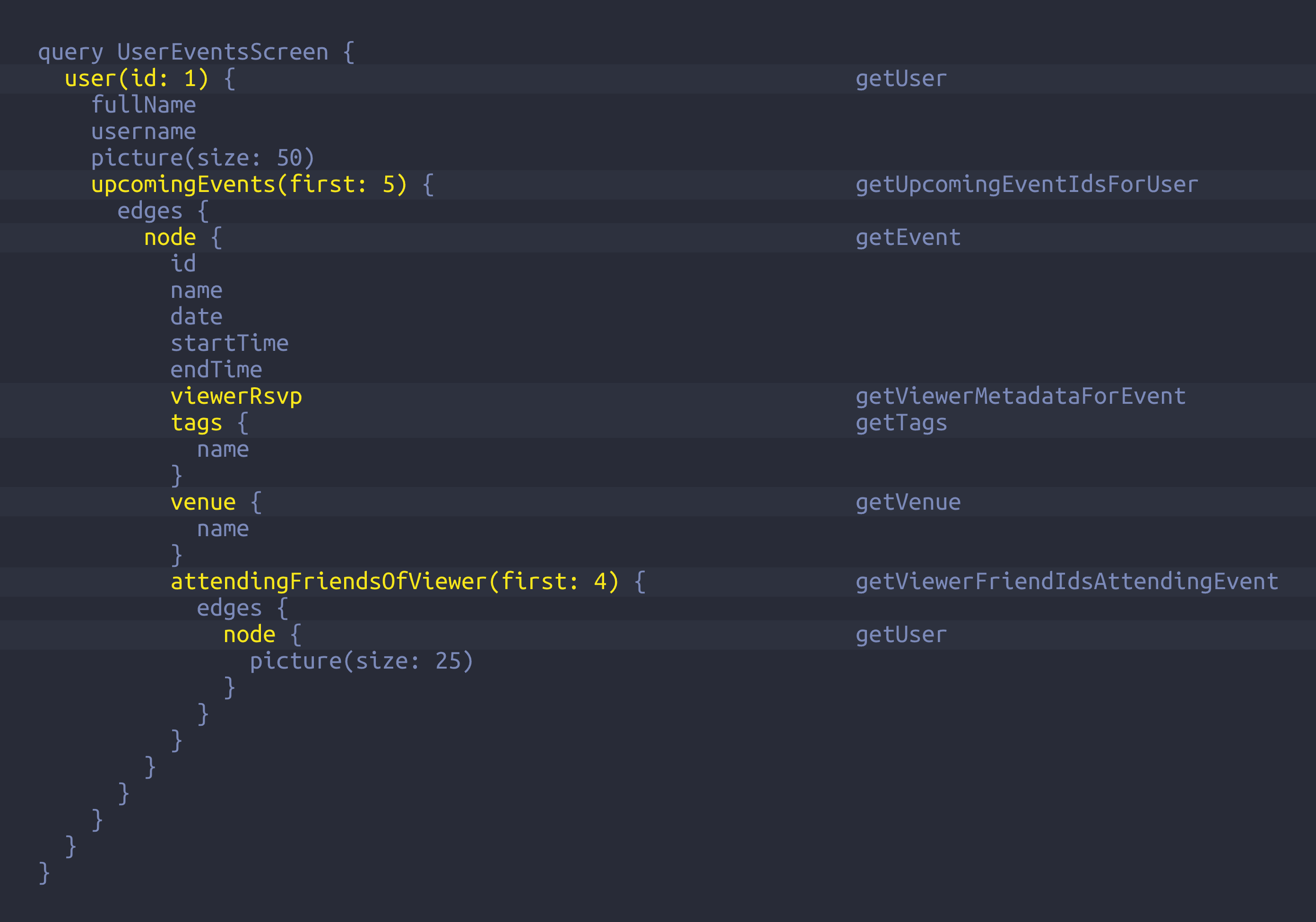
Version 1: Simple but slow
Let’s start with the simplest implementation. I’m assuming you have some knowledge of resolver functions, but essentially when resolving any field you have access to its parent object and its arguments (if any). The default resolver for any field is to look up the field’s own name on the parent — the best resolver is the default resolver. But when you want to get related data, you’ll typically make an asynchronous (non-blocking) request to your backend. We end up with a series of calls that looks like this:
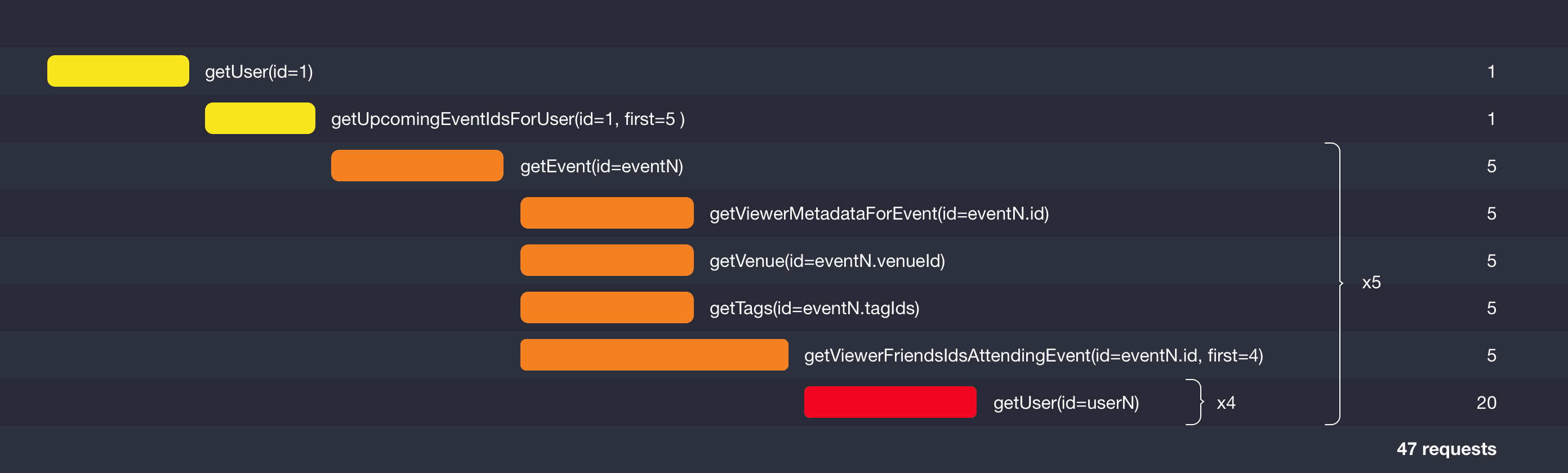
This isn’t great, and in reality it’s likely to be much worse. We’re looking at 20 potentially concurrent requests to getUser alone. If our UI were to go deeper we’d be dealing with hundreds of requests for the overall query. This level of overhead for a single client query is extremely undesirable.
Note: You may be wondering why we don’t have getUpcomingEventIdsForUser return the events themselves rather than just the IDs, and similarly for getViewerFriendIdsAttendingEvent. Surely this would result in far fewer requests? You’d be correct, and you may choose to approach it either way. I split up the concerns because, in my projects, the data for edges often lives in a different service from the node data itself. Additionally, if your data contains a lot of repetition (i.e you see the same event or user multiple times in a single query), splitting things up may perform better. When I’ve had scenarios where I’m certain there’ll be no repetition due to uniqueness (e.g comments for a blog post), I’ve handled it as a single request.
Version 2: Batching up the nodes
We need to start batching up some of these requests: instead of asking for one thing at a time, we can ask for multiple. Most backend stores should allow for some kind of batch lookups; for SQL it might be an ‘IN’ query, whilst for Redis it would be an MGET. We want to be using these capabilities, rather than forcing them to handle numerous concurrent calls for one item at a time.
What might not be clear from the previous timeline, is that each iteration of a level of nested calls can complete at different times. We could be fetching the venue for event 2 before we’ve even finished fetching event 1. We want to avoid this as much as possible, because the more things we keep in sync, the more data requirements we can batch up.
For our nodes (users, events, venues and tags), as long as we have some way to collect their IDs, we can easily switch them over to using batch calls:
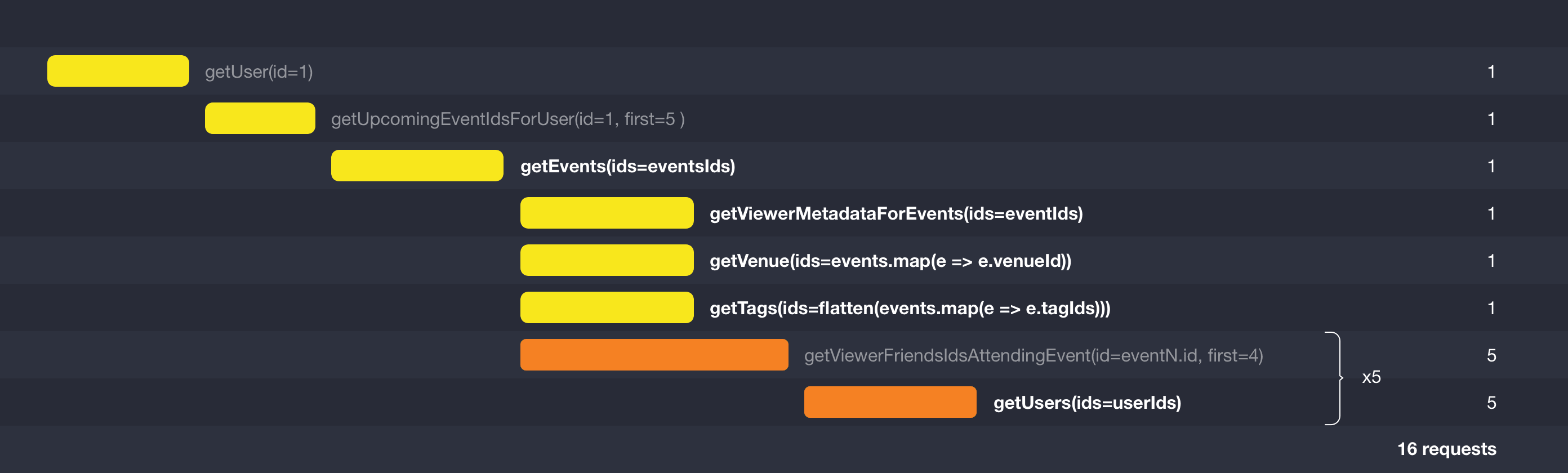
Technical interlude
The “how” of batching is going to vary depending on which language and GraphQL implementation you’re using. Some implementations come with native support, whilst others require you to come up with your own solutions or use a library. Here are some of the approaches I’m aware of
JavaScript: If you’re using graphql-js, there are two main options: dataloader and graphql-resolve-batch. I’ve been able to achieve everything in this article using dataloader.
Scala: If you’re using Sangria, it comes with built-in support for batching via deferred value resolution.
Elixir: If you’re using Absinthe, there is a built-in batch API.
Ruby: If you’re using graphql-ruby, you can use lazy_resolve and graphql-batch
Version 3: Batching up the edges
We still have a call to getViewerFriendIdsAttendingEvent for each event, so there’s no reason why we can’t batch up this call as well. The reason people often don’t is that it’s possibly less obvious how you’d batch up the pagination aspect of connections; but, there’s no reason why you can’t. It may not always be possible for your backend to handle it efficiently, but it’s still better to push it down to being an implementation detail. By doing this, we can get rid of the last group of unnecessary calls.
Note: Depending on batch size, we may choose to split them up into more calls, as it’s likely there are upper limits to the efficiencies of batching.
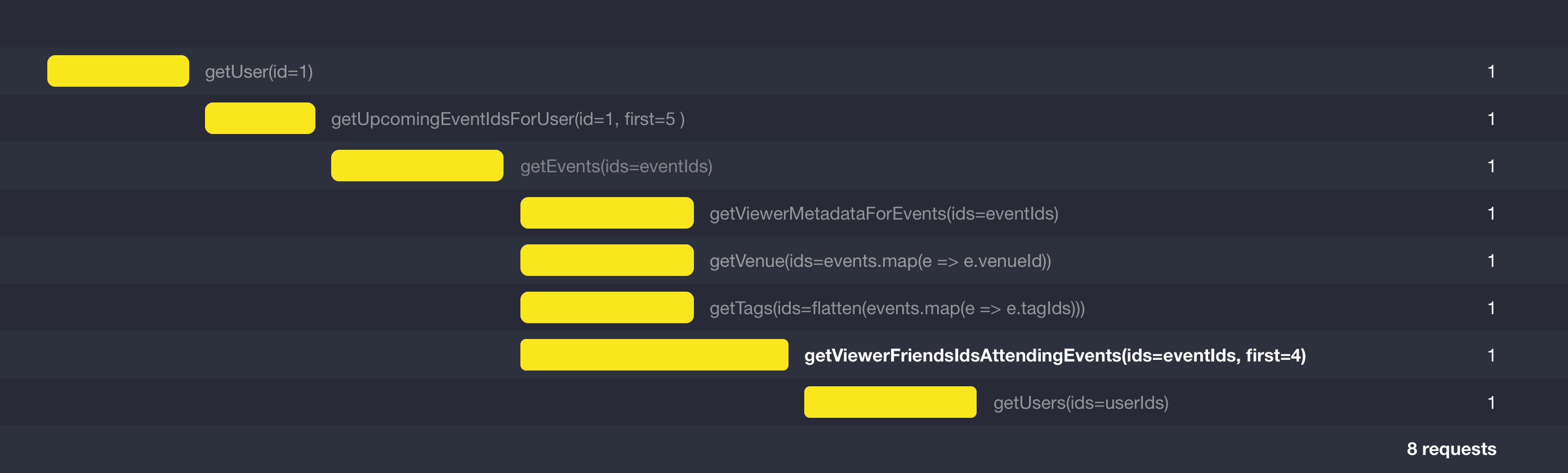
So, are we done now? We’ve minimized the number of calls we’re making to our backend, but there’s one more thing we can do.
Version 4: Looking ahead
The observant amongst you might have noticed that it’s still possible to make this faster. In fact, if you were writing a bespoke API to return this data, it’s likely you’d have already done it.
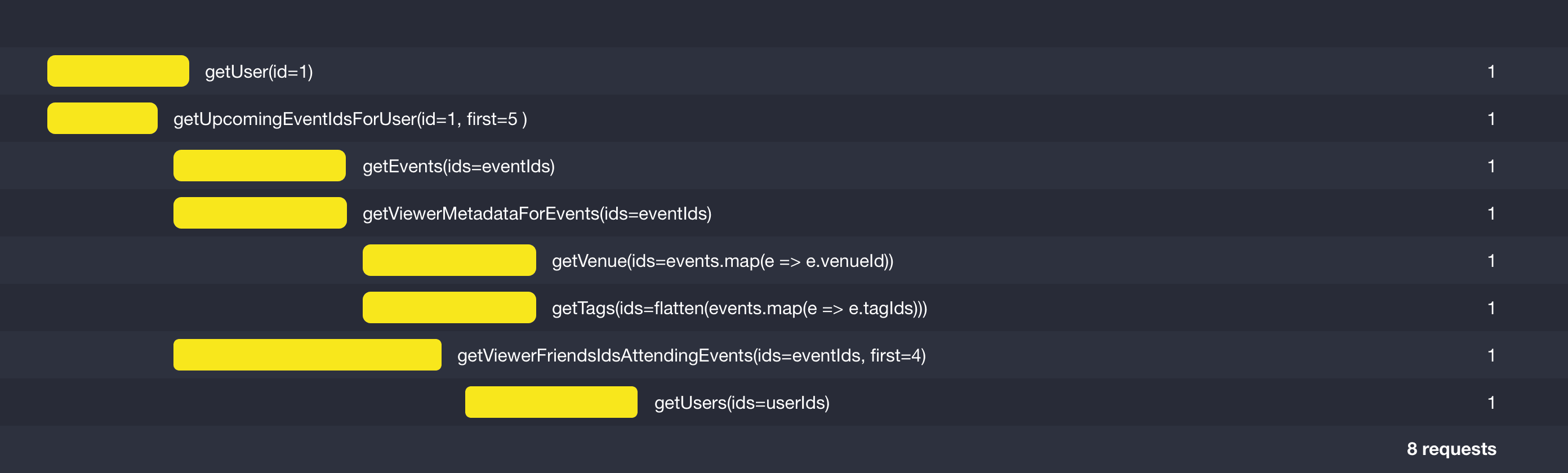
Wait, what just happened? Previously, we were making a lot of calls after others had completed, because the GraphQL execution model traverses the tree represented by the query, resolving children only after the parent is ready. But in many situations, we don’t actually need the data from the parent in order to successfully make some of the calls for its descendants. In this particular case, we don’t need the user before requesting their events — the only required data is the user ID, which we already have. Likewise, we don’t need to wait for the events to load before requesting their attendees — e have the required list of event IDs. The end result is a response time that is a significant improvement on what we had previously.
The lesson here, is that whilst GraphQL lends itself to loading data at the point a field is being resolved, this isn’t suitable for an optimized chain of requests. But in all GraphQL implementations I’ve looked into (graphql-js, Absinthe and Sangria) it’s possible to look down the query AST for descendant fields and know what data is going to be needed, and therefore request it early.
One caveat that should be considered is that if some of the fields don’t have value (maybe an event or user doesn’t exist), you may end up never using some of the data you’ve requested. If your miss rate is high (maybe your website has an unusually high 404 rate), this might be inefficient. But I expect that for most scenarios this won’t be a major issue.
This has been a high-level look into optimizing GraphQL from the perspective of data requests. I like to work from this perspectivea as it gives good insight into where the big performance wins are — if you can easily visualize the critical chains of requests, it’s easier to focus your efforts. For example, we can look at our final solution and see that we’d get the most value from improving the response time of getUpcomingEventsForUser and getViewerFriendsIdsAttendingEvent. In our original solution, we might have prioritized improving getUser instead.
For those Attending a Coding Bootcamp
First, bit of background. I’m someone who taught himself how to build websites in the mid-90s. I did a Computer Science degree at one of the top universities in the UK, and I’ve been working professio…
My Thoughts on Inline Styles
React’s favoured approach to defining component markup (i.e. JSX) isn’t as controversial as it was 3 years ago when people caught their first glimpse of it. There are still many who dislike it out of …